Sampling dan Pembuatan Data Sintetik dengan Numpy
Selain Pandas dan Matplotlib, module eksternal selanjutnya yang populer pada pemrograman Python adalah Numpy. Numpy adalah module yang memiliki banyak fungsi untuk melakukan operasi matematika pada vector (array) dan matriks secara efisien. Module ini banyak digunakan untuk mengembangkan berbagai metode matematika, statistika dan data science. Pada website resminya, kita bisa melihat banyak module-module eksternal yang menggunakan Numpy sebagai fondasi implementasinya.
Dalam kegiatan analisis data sehari-hari, sejujurnya tidak banyak contoh kasus di mana kita perlu langsung menggunakan Numpy. Kalaupun kita butuh menggunakan metode analisis data yang lebih advanced, biasanya lebih mudah untuk memakai module eksternal lain yang sudah menggunakan Numpy di dalamnya.
Meskipun demikian, karena banyak sekali contoh kode Python di internet yang menggunakan module ini, belajar sedikit mengenai Numpy akan tetap berguna. Sehingga pada chapter ini, kita akan belajar mengenal Numpy dengan mengimplementasikan beberapa teknik untuk membuat data sintetik (deret dan random) dan melakukan sampling pada data.
Untuk melakukan instalasi module numpy, buka program CMD.exe Prompt lewat Anaconda Navigator, lalu jalankan perintah di bawah ini:
conda install numpySetelah itu, jalankan aplikasi Spyder dari Anaconda Navigator dan tulis kode di bawah ini untuk melakukan impor module numpy:
import numpy as npData structure array
Numpy memiliki data structure khusus untuk merepresentasikan vector dan matriks dalam matematika, yaitu array. Value di dalam array ini hanya dapat berupa angka saja.
Berikut adalah beberapa contoh penggunaan array untuk pembuatan matriks:
import numpy as np
# representasi matrix 1 dimensi (vector)
data = np.array([1, 2, 3, 4])
print(data)
# Output:
# array([1, 2, 3, 4])
# representasi matrix 2x2 dimensi
data = np.array([[1, 2], [3, 4]])
print(data)
# Output:
# array([[1, 2],
# [3, 4]])
# representasi matrix 3x3 dimensi
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(data)
# Output:
# array([[1, 2, 3],
# [4, 5, 6],
# [7, 8, 9]])Seperti halnya list, akses value pada array dapat dilakukan menggunakan index:
data = np.array([[1, 2], [3, 4]])
print(data[0])
# [1 2]
print(data[0][0])
# 1Untuk mendapatkan informasi dimensi dari sebuah variable array, kita dapat menggunakan property dim pada variable tsb.:
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(data.shape)
# (3, 3)Semua operasi yang bisa dilakukan pada aljabar matriks dapat dilakukan menggunakan array seperti contoh berikut:
d1 = np.array([[1, 2], [3, 4]])
d2 = np.array([[3, 4], [5, 6]])
d3 = np.array([2, 2])
# penjumlahan
result = d1 + d2
print(result)
# Output:
# [[ 4 6]
# [ 8 10]]
# perkalian
result = d3 * d1
print(result)
# Output:
# [[2 4]
# [6 8]]
# transpose
result = np.transpose(d1)
print(result)
# Output:
# [[1 3]
# [2 4]]Seperti halnya Series pada Pandas, ringkasan statistik juga bisa didapatkan dari array menggunakan fungsi-fungsi pada Numpy. Bedanya, fungsi-fungsi statistik pada Numpy dapat bekerja dengan dimensi array yang besar dan kompleks sekalipun. Perhatikan contoh di bawah ini:
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(np.mean(data))
# Output:
# 5.0
print(np.median(data))
# Output:
# 5.0
print(np.quantile(data, 0.75))
# Output:
# 7.0
print(np.std(data))
# Output:
# 2.581988897471611Contoh sebelumnya menunjukkan bahwa secara default, ringkasan statistik didapatkan dengan sebelumnya mentransformasi array menjadi 1 dimensi terlebih dahulu. Kita juga bisa mengatur ringkasan statistik sesuai dengan axis seperti contoh berikut:
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(np.mean(data, axis = 0))
# Output:
# [4. 5. 6.]
print(np.mean(data, axis = 1))
# Output:
# [2. 5. 8.]Deret dan distribusi statistika
Pada course algoritma, kita telah belajar menggunakan fungsi range untuk pembuatan data deret secara cepat:
data = list(range(0, 5))
print(data)
# Output:
# [0, 1, 2, 3, 4]Numpy juga bisa digunakan untuk menghasilkan data deret. Faktanya, Numpy menyediakan fungsi yang lebih lengkap untuk kebutuhan ini. Perhatikan contoh berikut ini:
data = np.arange(0, 5)
print(data)
# Output:
# [0 1 2 3 4]
# Parameter step digunakan untuk mengatur jarak antar nilai pada deret
data = np.arange(0, 5, step = 0.5)
print(data)
# Output:
# [0. 0.5 1. 1.5 2. 2.5 3. 3.5 4. 4.5]
# Pembuatan deret dengan nilai 0
data = np.zeros(5)
print(data)
# Output:
# [0. 0. 0. 0. 0.]
# Pembuatan matrix 3x3 dengan nilai 0
data = np.zeros([3, 3])
print(data)
# Output:
# [[0. 0. 0.]
# [0. 0. 0.]
# [0. 0. 0.]]
# Pembuatan deret dengan nilai 1
data = np.ones(5)
print(data)
# Output:
# [1. 1. 1. 1. 1.]
# Pembuatan matrix 3x3 dengan nilai 1
data = np.ones([3, 3])
print(data)
# Output:
# [[1. 1. 1.]
# [1. 1. 1.]
# [1. 1. 1.]]
print(np.array([3, 3, 3]) * data)
# Output:
# [[3. 3. 3.]
# [3. 3. 3.]
# [3. 3. 3.]]Deret aritmatika lain juga bisa dibuat dengan menggunakan fungsi-fungsi Numpy seperti pada contoh berikut:
# Deret linear
data = np.linspace(1, 100, num = 10)
print(data)
# Output:
# [ 1. 12. 23. 34. 45. 56. 67. 78. 89. 100.]
# Deret logaritma
data = np.logspace(1, 100, num = 10, base = 2)
print(data)
# Output:
# [2.00000000e+00 4.09600000e+03 8.38860800e+06 1.71798692e+10
# 3.51843721e+13 7.20575940e+16 1.47573953e+20 3.02231455e+23
# 6.18970020e+26 1.26765060e+30]
# Deret geometrik
data = np.geomspace(1, 100, num = 10)
print(data)
# Output:
# [ 1. 1.66810054 2.7825594 4.64158883 7.74263683
# 12.91549665 21.5443469 35.93813664 59.94842503 100. ]Numpy juga menyediakan berbagai macam fungsi untuk membuat data array dengan nilai random menggunakan distribusi statistika. Perhatikan contoh kode di bawah ini:
gen = np.random.default_rng(123)
# Distribusi normal
mu, sigma = 0, 0.1
data = gen.normal(mu, sigma, size = 10)
print(data)
# Output:
# [-0.09891214 -0.03677867 0.12879253 0.01939744 0.09202309
# 0.05771038 -0.06364636 0.05419522 -0.03165955 -0.03223891]
# Distribusi uniform
low, high = 0, 1
data = gen.uniform(low, high, size = 10)
print(data)
# Output:
# [0.51297046 0.2449646 0.8242416 0.21376296 0.74146705
# 0.6299402 0.92740726 0.23190819 0.79912513 0.51816504]
# Distribusi poisson
lmd = 5
data = gen.poisson(lmd, size = 10)
print(data)
# Output:
# [ 4 2 10 3 3 3 1 7 4 8]Apabila kita coba visualisasikan menggunakan histogram, bentuk distribusinya akan terlihat seperti contoh berikut:
import matplotlib.pyplot as plt
import numpy as np
gen = np.random.default_rng(123)
# Distribusi normal
mu, sigma = 0, 0.1
data = gen.normal(mu, sigma, size = 1000)
fig, ax = plt.subplots()
ax.hist(data, bins = 20)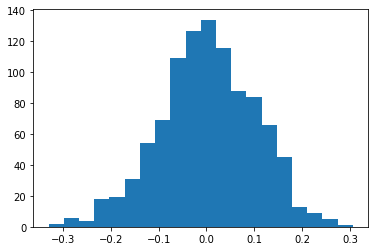
import matplotlib.pyplot as plt
import numpy as np
gen = np.random.default_rng(123)
# Distribusi poisson
lmd = 5
data = gen.poisson(lmd, size = 1000)
fig, ax = plt.subplots()
ax.hist(data)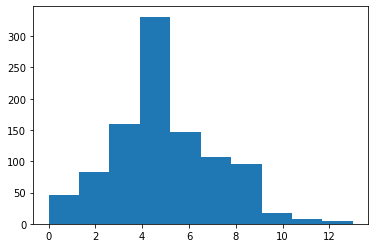
Data yang dibuat oleh Numpy seringkali digunakan untuk menginisialisasi sebuah DataFrame pada Pandas. Di bawah ini adalah contoh pembuatan data sintetik untuk nilai ujian dengan distribusi normal:
import pandas as pd
import numpy as np
gen = np.random.default_rng(123)
# Distribusi normal dengan mean = 50 dan std_dev = 15
math_scores = gen.normal(50, 15, size = 100)
# Pastikan range nilainya antara 0-100
math_scores = np.clip(math_scores, 0, 100)
# Lakukan pembulatan
math_scores = np.round(math_scores)
# Distribusi normal dengan mean = 64 dan std_dev = 10
bio_scores = gen.normal(64, 10, size = 100)
bio_scores = np.clip(bio_scores, 0, 100)
bio_scores = np.round(bio_scores)
data = pd.DataFrame({
'math': math_scores,
'bio': bio_scores,
})
print(data)
# Output:
# math bio
# 0 35.0 59.0
# 1 44.0 81.0
# 2 69.0 61.0
# 3 53.0 50.0
# 4 64.0 61.0
# .. ... ...
# 95 32.0 66.0
# 96 45.0 62.0
# 97 32.0 53.0
# 98 62.0 69.0
# 99 63.0 47.0
#
# [100 rows x 2 columns]
print(data.describe())
# Output:
# math bio
# count 100.00000 100.000000
# mean 51.16000 65.000000
# std 13.49502 9.223378
# min 17.00000 37.000000
# 25% 42.75000 59.750000
# 50% 50.00000 65.000000
# 75% 62.00000 71.000000
# max 84.00000 87.000000Teknik Sampling
Module Numpy juga umum digunakan untuk melakukan sampling terhadap data. Untuk mendapatkan sample secara random dari data, kita dapat memanfaatkan fungsi choice seperti contoh berikut:
import pandas as pd
import numpy as np
gen = np.random.default_rng(123)
# buat list dengan value 1-10
data = np.linspace(1, 10, num = 10)
for i in range(5):
# ambil sample sebanyak 5
sample = gen.choice(data, 5)
print(sample)
# Output:
# [1. 7. 6. 1. 10.]
# [3. 3. 2. 4. 2.]
# [4. 9. 5. 10. 5.]
# [3. 8. 9. 9. 9.]
# [1. 6. 3. 3. 3.]Secara default, fungsi choice akan melakukan sampling dengan pengembalian. Hal ini terlihat dari hasil sample yang berulang pada contoh di atas. Untuk melakukan sampling tanpa pengembalian, kita dapat mengeset parameter replace dengan nilai False:
import pandas as pd
import numpy as np
gen = np.random.default_rng(123)
data = np.linspace(1, 10, num = 10)
for i in range(5):
sample = gen.choice(data, 5, replace = False)
print(sample)
# Output:
# [9. 8. 1. 10. 5.]
# [2. 5. 10. 3. 7.]
# [5. 3. 1. 6. 7.]
# [3. 2. 7. 9. 6.]
# [8. 2. 5. 6. 7.]Value yang terpilih dalam sample memiliki probabilitas yang sama untuk semua value. Apabila diperlukan, sampling juga bisa diatur agar mengikuti probabilitas yang berbeda-beda untuk tiap value di dalam data melalui parameter p seperti contoh di bawah ini.
import pandas as pd
import numpy as np
gen = np.random.default_rng(123)
data = np.linspace(1, 10, num = 10)
probs = [0.025, 0.025, 0.1, 0.25, 0.25, 0.1, 0.1, 0.05, 0.05, 0.05]
for i in range(5):
sample = gen.choice(data, 5, p = probs)
print(sample)
# Output:
# [6. 3. 4. 4. 4.]
# [7. 9. 4. 7. 8.]
# [5. 4. 7. 4. 6.]
# [5. 9. 4. 7. 5.]
# [4. 4. 5. 5. 4.]Dengan menggunakan teknik yang sama, kita bisa melakukan sampling pada sebuah DataFrame. Caranya, ambil sample list dari index DataFrame, lalu lakukan filtering terhadap DataFrame tsb. menggunakan sample index. Contoh berikut memperlihatkan cara mengambil sampel sebanyak 10 rows dari data titanic.
import pandas as pd
import numpy as np
df = pd.read_csv('https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv', delimiter = ',')
gen = np.random.default_rng(123)
sample_size = 10
sample_indexes = gen.choice(df.index, sample_size)
df_sample = df[df.index.isin(sample_indexes)]
print(df_sample)
# Output:
# PassengerId Survived Pclass ... Fare Cabin Embarked
# 13 14 0 3 ... 31.2750 NaN S
# 47 48 1 3 ... 7.7500 NaN Q
# 156 157 1 3 ... 7.7333 NaN Q
# 164 165 0 3 ... 39.6875 NaN S
# 196 197 0 3 ... 7.7500 NaN Q
# 227 228 0 3 ... 7.2500 NaN S
# 297 298 0 1 ... 151.5500 C22 C26 S
# 528 529 0 3 ... 7.9250 NaN S
# 607 608 1 1 ... 30.5000 NaN S
# 809 810 1 1 ... 53.1000 E8 S
#
# [10 rows x 12 columns]Numpy juga dapat digunakan untuk membantu menganalisis data dengan metode statistika seperti regresi linier dan pengujian hipotesis. Penggunaan metode statistika dengan Numpy dan module eksternal Python lainnya akan dibahas lebih dalam pada course Statistika dan Machine Learning Dasar dengan Python (segera hadir).